Istio - 데이터 플레인 트러블슈팅¶
Istio 데이터 플레인의 트러블슈팅 도구와 Envoy 설정 검증 방법을 정리한다.
Kubernetes 환경에서 Istio 데이터 플레인 트러블슈팅을 다룬다. 실제 현장에서 자주 발생하는 문제들을 진단하고 해결하는 방법을 실습 중심으로 정리한다.
1. 데이터 플레인 디버깅의 기초¶
1.1 Istio 구성 요소 이해하기¶
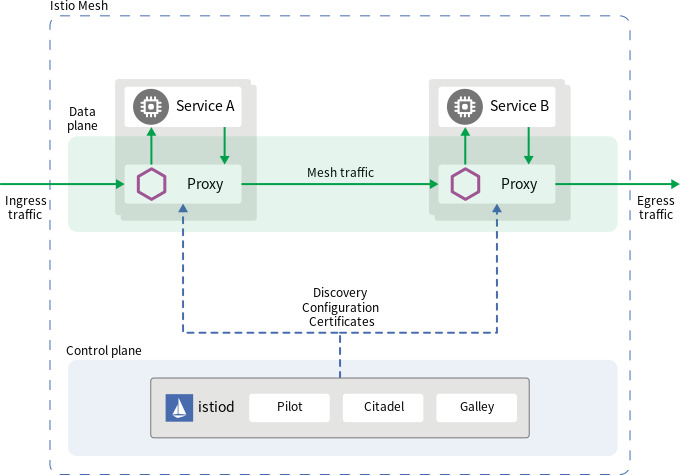
Istio 서비스 메시에서 데이터 플레인은 모든 서비스 간 네트워크 통신의 실제 실행자이다. 데이터가 흐르는 경로와 그 흐름을 제어하는 역할을 담당하며, 복잡한 구성으로 인해 다양한 문제가 발생할 수 있다.
효과적인 디버깅을 위해서는 다음 구성 요소들의 상호작용을 이해해야 한다:
-
istiod: 컨트롤 플레인으로, 설정을 데이터 플레인에 배포하고 관리한다. 모든 프록시에게 최신 설정을 전달한다.
-
인그레스 게이트웨이: 외부 트래픽을 메시로 유입시키는 진입점이다. 외부에서 들어오는 모든 트래픽을 수신하여 내부로 전달한다.
-
서비스 프록시(사이드카): 각 워크로드에 주입되어 워크로드 간 통신을 중재하는 Envoy 프록시이다.
-
워크로드: 실제 비즈니스 로직을 수행하는 애플리케이션이다.
예기치 못한 문제는 이 체인의 어떤 구성 요소와도 관련 있을 수 있으므로, 각 구성 요소의 역할과 상호작용을 이해해야 한다. 특히 대부분의 데이터 플레인 이슈는 Envoy 프록시 설정의 문제로 귀결되므로, Envoy 프록시의 설정과 작동 방식을 이해하는 것이 중요한다.
1.2 실습 환경 설정¶
이론만으로는 서비스 메시의 복잡한 문제를 해결하기 어렵다. 직접 문제 상황을 재현하고 해결해보는 것이 가장 효과적인 학습 방법이다. 그래서 우리는 먼저 실습 환경을 구축하겠다.
이 실습을 위해 다음과 같은 환경을 구성한다:
Step 1: Kubernetes 클러스터 생성
# kind 클러스터 생성 (이미 있다면 생략)
kind create cluster --name myk8s --image kindest/node:v1.23.17 --config - <<EOF
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
extraPortMappings:
- containerPort: 30000 # Sample Application (istio-ingrssgateway) HTTP
hostPort: 30000
- containerPort: 30001 # Prometheus
hostPort: 30001
- containerPort: 30002 # Grafana
hostPort: 30002
- containerPort: 30003 # Kiali
hostPort: 30003
- containerPort: 30004 # Tracing
hostPort: 30004
- containerPort: 30005 # Sample Application (istio-ingrssgateway) HTTPS
hostPort: 30005
networking:
podSubnet: 10.10.0.0/16
serviceSubnet: 10.200.0.0/22
EOF
Step 2: Istio 1.17.8 설치
# Istio 다운로드 및 설치
export ISTIOV=1.17.8
curl -L https://istio.io/downloadIstio | ISTIO_VERSION=$ISTIOV sh -
cd istio-$ISTIOV/
bin/istioctl install --set profile=demo --set values.global.proxy.privileged=true -y
# 부가 모니터링 도구 설치
kubectl apply -f samples/addons/
# 실습 네임스페이스 생성 및 자동 사이드카 주입 설정
kubectl create ns istioinaction
kubectl label namespace istioinaction istio-injection=enabled
# 인그레스 게이트웨이 NodePort 설정
kubectl patch svc -n istio-system istio-ingressgateway -p '{"spec": {"type": "NodePort", "ports": [{"port": 80, "targetPort": 8080, "nodePort": 30000}]}}'
kubectl patch svc -n istio-system istio-ingressgateway -p '{"spec": {"type": "NodePort", "ports": [{"port": 443, "targetPort": 8443, "nodePort": 30005}]}}'
kubectl patch svc -n istio-system istio-ingressgateway -p '{"spec":{"externalTrafficPolicy": "Local"}}'
# 모니터링 도구 NodePort 설정
kubectl patch svc -n istio-system prometheus -p '{"spec": {"type": "NodePort", "ports": [{"port": 9090, "targetPort": 9090, "nodePort": 30001}]}}'
kubectl patch svc -n istio-system grafana -p '{"spec": {"type": "NodePort", "ports": [{"port": 3000, "targetPort": 3000, "nodePort": 30002}]}}'
kubectl patch svc -n istio-system kiali -p '{"spec": {"type": "NodePort", "ports": [{"port": 20001, "targetPort": 20001, "nodePort": 30003}]}}'
kubectl patch svc -n istio-system tracing -p '{"spec": {"type": "NodePort", "ports": [{"port": 80, "targetPort": 16686, "nodePort": 30004}]}}'
Istio 설치가 완료되면 기본적인 모니터링 도구들도 함께 설치된다. 이 도구들은 트러블슈팅 시 활용한다:
- Prometheus: 메트릭 수집 및 저장
- Grafana: 시각화된 대시보드
- Kiali: 서비스 메시 토폴로지 및 설정 검증
- Jaeger: 분산 트레이싱
Step 3: 모니터링 도구 접속 확인
# 각 도구의 대시보드에 접근하여 설치 확인
echo "Prometheus: http://localhost:30001"
echo "Grafana: http://localhost:30002"
echo "Kiali: http://localhost:30003"
echo "Jaeger Tracing: http://localhost:30004"
# 각 URL을 브라우저에서 열고 접속 확인
참고: 실제 환경에서는 모니터링 도구들에 대한 적절한 접근 제어와 보안 설정이 필수적이다. 프로덕션 환경에서는 인증과 권한 관리를 반드시 설정해야 한다.
이제 실습 환경이 준비되었다. 다음 섹션에서는 실제 서비스 메시 운영 중 발생할 수 있는 다양한 문제 상황을 재현하고 해결한다.
2. 실습: 잘못 설정된 데이터 플레인 문제 해결¶
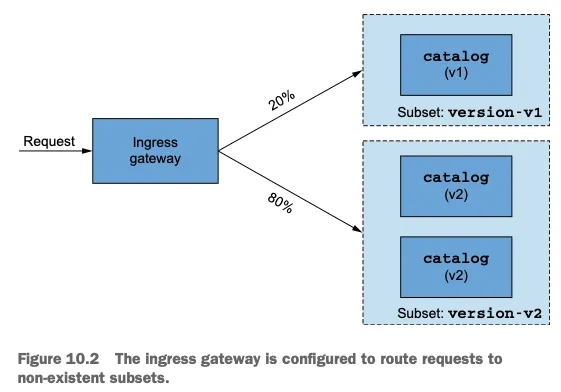
2.1 문제 상황 재현: 누락된 부분집합(Subset) 설정¶
실제 현장에서 가장 흔하게 발생하는 Istio 설정 오류 중 하나는 부분집합(Subset) 정의 누락이다. 이 문제는 신규 배포나 업데이트 과정에서 자주 발생하며, 특히 여러 팀이 서로 다른 구성 요소를 담당할 때 더 빈번하게 나타난다.
이제 이 상황을 직접 재현한다.
Step 1: 샘플 애플리케이션 배포
# 먼저 기존 배포가 있다면 정리
kubectl delete -n istioinaction deploy,svc,gw,vs,dr --all
# 필요한 샘플 애플리케이션 구성 요소 배포
kubectl apply -f services/catalog/kubernetes/catalog.yaml -n istioinaction # catalog v1 배포
kubectl apply -f ch10/catalog-deployment-v2.yaml -n istioinaction # catalog v2 배포
kubectl apply -f ch10/catalog-gateway.yaml -n istioinaction # catalog-gateway 배포
kubectl apply -f ch10/catalog-virtualservice-subsets-v1-v2.yaml -n istioinaction # 부분집합을 참조하나 정의가 없는 VirtualService
여기서 주의 깊게 봐야 할 부분은 마지막 설정 파일이다. catalog-virtualservice-subsets-v1-v2.yaml에는 두 개의 부분집합(version-v1, version-v2)을 참조하고 있지만, 이에 해당하는 DestinationRule을 적용하지 않았다. 이것이 바로 우리가 재현하려는 문제 상황이다.
Step 2: Gateway와 VirtualService 구성 확인
# Gateway 정의 확인
kubectl get gateway -n istioinaction
kubectl get gateway catalog-gateway -n istioinaction -o yaml
# VirtualService 정의 확인
kubectl get virtualservice -n istioinaction
kubectl get virtualservice catalog-v1-v2 -n istioinaction -o yaml
VirtualService 정의를 살펴보면 다음과 같은 내용이 포함되어 있다:
spec:
hosts:
- "catalog.istioinaction.io"
gateways:
- "catalog-gateway"
http:
- route:
- destination:
host: catalog.istioinaction.svc.cluster.local
subset: version-v1 # <-- 이 부분집합이 정의되어 있지 않음!
port:
number: 80
weight: 20
- destination:
host: catalog.istioinaction.svc.cluster.local
subset: version-v2 # <-- 이 부분집합이 정의되어 있지 않음!
port:
number: 80
weight: 80
이 설정은 트래픽의 20%를 version-v1 부분집합으로, 80%를 version-v2 부분집합으로 라우팅하려고 시도한다. 그러나 이 부분집합들을 정의하는 DestinationRule이 없기 때문에 문제가 발생한다.
참고: 실제 운영 환경에서는 VirtualService와 함께 필요한 DestinationRule을 함께 배포하거나, CI/CD 파이프라인에 검증 단계를 추가하는 것이 좋다.
Step 3: 문제 확인 - 서비스에 접근 시도
# 호스트 파일 설정 (필요한 경우)
echo "127.0.0.1 catalog.istioinaction.io" | sudo tee -a /etc/hosts
# 서비스 접근 시도 - 503 Service Unavailable 에러 발생
curl -v http://catalog.istioinaction.io:30000/items

결과적으로 503 에러가 반환된다. 표면적으로는 오류 원인을 파악하기 어렵다.
Step 4: 인그레스 게이트웨이 로그 확인
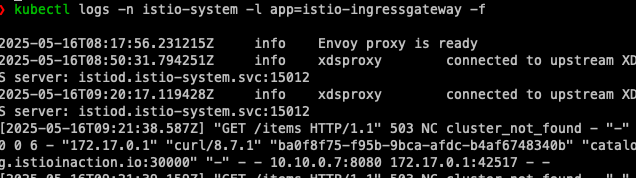
로그 출력 예시:
[2025-05-09T01:54:51.145Z] "GET /items HTTP/1.1" 503 NC cluster_not_found - "-" 0 0 0 - "172.18.0.1" "curl/8.7.1" "90a7d941-cbc4-91ae-9da1-bc95695d5c50" "catalog.istioinaction.io" "10.10.0.7:8080" outbound|80|version-v2|catalog.istioinaction.svc.cluster.local 10.10.0.14:46182 172.18.0.2:8080 172.18.0.1:58242 - -
여기서 중요한 부분은 503 NC cluster_not_found이다. 이는 요청을 처리할 클러스터(부분집합)를 찾을 수 없다는 의미이다. 'NC'는 'No Cluster'의 약자로, Envoy 프록시가 트래픽을 라우팅할 목적지를 찾지 못했음을 나타낸다.
이제 문제를 발견했으니, 더 자세히 진단하고 해결해 보겠다.
2.2 다양한 도구를 사용한 문제 진단¶
예상대로 우리의 샘플 애플리케이션은 정상적으로 동작하지 않고 503 에러를 반환했다. 이제 Istio가 제공하는 다양한 진단 도구를 활용해 문제의 근본 원인을 찾아보겠다.
2.2.1 istioctl analyze로 설정 검증¶
Istio는 istioctl analyze 명령어를 통해 설정 오류를 자동으로 감지할 수 있는 강력한 도구를 제공한다. 이 도구는 100개가 넘는 검증 규칙을 사용해 잠재적인 문제를 식별한다.
Step 1: istioctl analyze 명령어로 설정 오류 확인
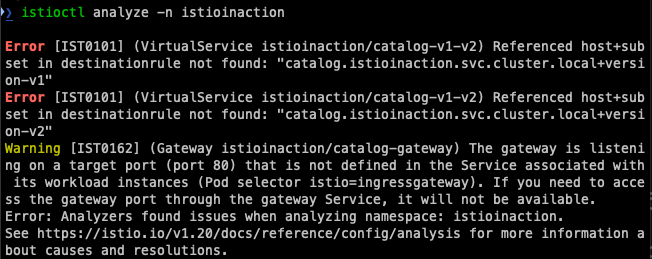
출력 예시:
Error [IST0101] (VirtualService istioinaction/catalog-v1-v2) Referenced host+subset in destinationrule not found: "catalog.istioinaction.svc.cluster.local+version-v1"
Error [IST0101] (VirtualService istioinaction/catalog-v1-v2) Referenced host+subset in destinationrule not found: "catalog.istioinaction.svc.cluster.local+version-v2"
Error: Analyzers found issues when analyzing namespace: istioinaction.
See https://istio.io/v1.17/docs/reference/config/analysis for more information about causes and resolutions.
이 출력은 의심했던 정확한 문제를 확인해준다. IST0101 오류 코드는 "참조된 host+subset이 DestinationRule에서 찾을 수 없음"을 의미한다.
2.2.2 istioctl describe로 워크로드 설정 검사¶
istioctl analyze가 전체 설정을 검사했다면, istioctl describe를 사용하여 특정 파드나 서비스의 관점에서 문제를 살펴볼 수 있다. 이 명령어는 특정 워크로드에 적용된 모든 Istio 설정을 보여준다.
Step 1: 문제가 있는 파드 식별
kubectl get pod -n istioinaction -l app=catalog
CATALOG_POD1=$(kubectl get pod -n istioinaction -l app=catalog -o jsonpath='{.items[0].metadata.name}')
echo $CATALOG_POD1
docker exec -it myk8s-control-plane istioctl x des pod -n istioinaction $CATALOG_POD1
Step 2: istioctl describe로 파드 설정 검사
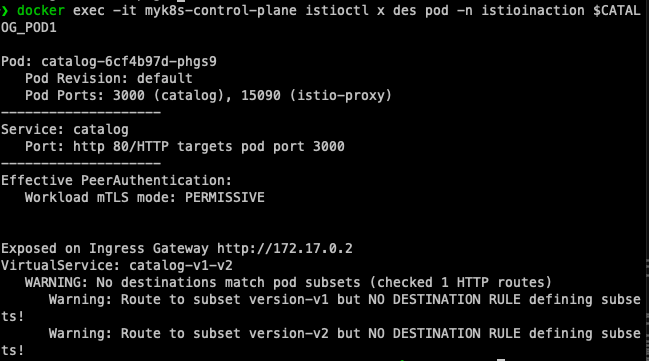
출력 예시:
Pod: catalog-6cf4b97d-l44zk
Pod Revision: default
Pod Ports: 3000 (catalog), 15090 (istio-proxy)
--------------------
Service: catalog
Port: http 80/HTTP targets pod port 3000
--------------------
Effective PeerAuthentication:
Workload mTLS mode: PERMISSIVE
Exposed on Ingress Gateway http://172.18.0.2
VirtualService: catalog-v1-v2
WARNING: No destinations match pod subsets (checked 1 HTTP routes)
Warning: Route to subset version-v1 but NO DESTINATION RULE defining subsets!
Warning: Route to subset version-v2 but NO DESTINATION RULE defining subsets!
이 출력에서 볼 수 있듯이, 파드는 VirtualService에 의해 노출되지만 필요한 부분집합 정의가 없어 경고가 표시된다. 이것은 실제 서비스가 동작하지 않는 이유를 명확하게 보여준다.
참고:
istioctl x describe는 문제 해결 시 초기 진단 명령어로 활용하기 좋다. 워크로드에 적용된 Istio 설정을 다양한 측면에서 확인할 수 있다.
2.2.3 Kiali 대시보드를 사용한 시각적 진단¶
명령줄 도구는 강력하지만, 때로는 시각적인 도구가 문제를 더 명확하게 보여준다. Kiali는 Istio 서비스 메시를 위한 시각화 도구로, 설정 오류와 트래픽 문제를 직관적으로 확인할 수 있다.
Step 1: Kiali 대시보드 접속
Step 2: 이슈 찾기
1. 왼쪽 메뉴에서 'Overview'를 클릭한다.
2. 네임스페이스 목록에서 'istioinaction'을 찾아 클릭한다.
3. 네임스페이스 개요 화면에서 경고 아이콘을 확인한다. (노란색 삼각형 아이콘)
Step 3: 상세 이슈 확인 1. 왼쪽 메뉴에서 'Istio Config'를 클릭한다. 2. 'istioinaction' 네임스페이스에서 문제가 있는 VirtualService 'catalog-v1-v2' 확인한다. 3. 'catalog-v1-v2' 항목 옆의 경고 아이콘 위에 마우스를 올려 메시지를 확인한다.
출력 예시:
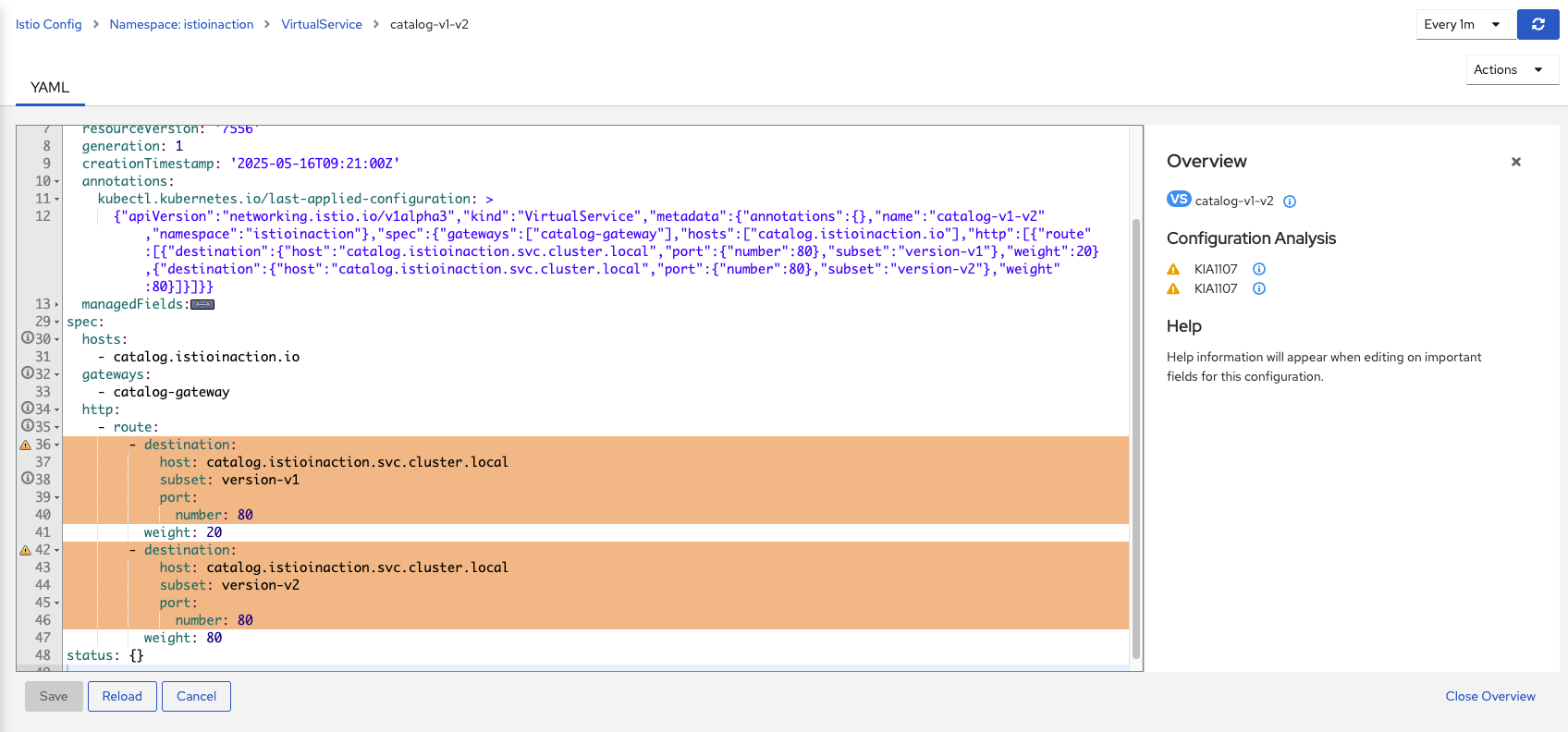
Kiali의 경고 메시지는 명확한다. VirtualService에서 참조하는 Subnet(부분집합)을 찾을 수 없다는 것이다. 이는 앞서 다른 도구들로 확인한 문제와 일치한다.

세 가지 방법으로 동일한 문제를 확인했다. VirtualService에서 참조하는 부분집합이 DestinationRule에 정의되어 있지 않은 것이 원인이다.
2.3 문제 해결: DestinationRule 적용¶
이제 문제의 원인을 명확히 파악했으니, 해결책도 명확한다. 누락된 DestinationRule을 생성하여 VirtualService에서 참조하는 부분집합을 정의해야 한다.
참고: Istio 트래픽 관리에서 VirtualService는 "어디로 갈지"를 정의하고, DestinationRule은 "어떻게 갈지"를 정의한다. 이 두 리소스는 항상 함께 고려해야 한다.
Step 1: DestinationRule YAML 파일 확인
출력 예시:
apiVersion: networking.istio.io/v1alpha3
kind: DestinationRule
metadata:
name: catalog
namespace: istioinaction
spec:
host: catalog.istioinaction.svc.cluster.local
subsets:
- name: version-v1
labels:
version: v1
- name: version-v2
labels:
version: v2
이 DestinationRule은:
1. catalog.istioinaction.svc.cluster.local 서비스를 대상으로 한다.
2. version-v1 부분집합은 version: v1 레이블이 있는 파드를 선택한다.
3. version-v2 부분집합은 version: v2 레이블이 있는 파드를 선택한다.
이것이 바로 우리가 필요한 설정이다. 이 DestinationRule은 VirtualService에서 참조하는 두 부분집합을 정의한다.
Step 2: 파일 적용 전에 istioctl analyze로 검증
출력 예시:
검증이 성공적으로 완료되었다. 이제 DestinationRule을 적용해 보겠다.
참고: 설정을 적용하기 전에
istioctl analyze로 검증하면 새로운 문제를 사전에 방지할 수 있다.
Step 3: DestinationRule 적용
출력 예시:
DestinationRule이 성공적으로 생성되었다. 이제 시스템이 VirtualService에서 참조하는 부분집합을 인식할 수 있게 되었다.
2.4 해결 확인¶
마지막 단계는 우리의 수정이 실제로 문제를 해결했는지 확인하는 것이다. 여러 방법으로 이를 검증해 보겠다.
Step 1: 서비스 기능 테스트
이제 서비스가 정상적으로 응답한다. 503 에러는 더 이상 발생하지 않다.
Step 2: istioctl로 클러스터 설정 확인
# 클러스터 설정 확인
istioctl proxy-config clusters deploy/istio-ingressgateway -n istio-system \
--fqdn catalog.istioinaction.svc.cluster.local --port 80
출력 예시:
SERVICE FQDN PORT SUBSET DIRECTION TYPE DESTINATION RULE
catalog.istioinaction.svc.cluster.local 80 - outbound EDS catalog.istioinaction
catalog.istioinaction.svc.cluster.local 80 version-v1 outbound EDS catalog.istioinaction
catalog.istioinaction.svc.cluster.local 80 version-v2 outbound EDS catalog.istioinaction
이제 version-v1과 version-v2 부분집합이 모두 올바르게 정의되었다. 인그레스 게이트웨이가 이 두 부분집합을 인식하고 있으며, 트래픽을 올바르게 라우팅할 수 있게 되었다.
Step 3: istioctl describe로 변경사항 확인
CATALOG_POD1=$(kubectl get pod -n istioinaction -l app=catalog -o jsonpath='{.items[0].metadata.name}')
istioctl x describe pod -n istioinaction $CATALOG_POD1
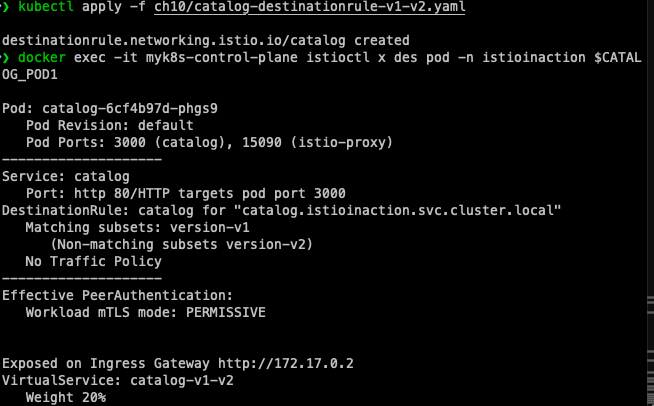
출력 예시:
Pod: catalog-6cf4b97d-l44zk
Pod Revision: default
Pod Ports: 3000 (catalog), 15090 (istio-proxy)
--------------------
Service: catalog
Port: http 80/HTTP targets pod port 3000
DestinationRule: catalog for "catalog.istioinaction.svc.cluster.local"
Matching subsets: version-v1
(Non-matching subsets version-v2)
No Traffic Policy
--------------------
VirtualService: catalog-v1-v2
Weight 20%
이제 경고가 사라졌고, 파드가 version-v1 부분집합에 속해 있는 것을 확인할 수 있다.
Step 4: Kiali에서 변경사항 확인
Kiali 대시보드에서도 문제가 해결되었는지 확인해보겠다.
- Kiali 대시보드에서 'Overview'로 이동한다.
- 'istioinaction' 네임스페이스를 선택한다.
- 이제 경고 아이콘이 없어진 것을 확인한다.

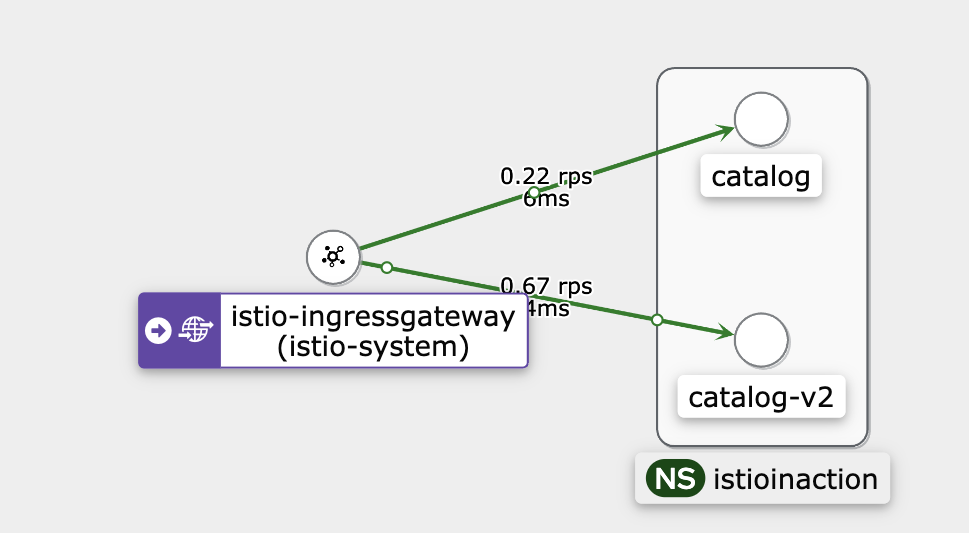
- 'Graph' 메뉴로 이동하여 서비스 간 트래픽 흐름을 확인한다.
- 'Display' 옵션에서 'Service Nodes', 'Traffic Animation'을 활성화한다.
- 트래픽이 'catalog-v1'과 'catalog-v2' 서비스로 분산되는 것을 확인한다.
Step 5: 부하 테스트로 트래픽 분산 확인
# 반복 요청으로 트래픽 분산 확인
for i in {1..20}; do
curl -s http://catalog.istioinaction.io:30000/items > /dev/null
echo "------------"
sleep 0.5
done
Step 6: Prometheus에서 메트릭 확인
Prometheus UI에서 다음 쿼리를 실행한다:
sum(istio_requests_total{destination_service_name="catalog", response_code="200"}) by (destination_workload)
이 쿼리는 catalog 서비스에 대한 성공적인 요청을 워크로드별로 보여준다.

이 결과에서 catalog-v2 워크로드의 요청이 특히 높은 것을 확인할 수 있다.
학습 포인트¶
이 실습을 통해 우리는 다음과 같은 중요한 교훈을 얻었다:
-
VirtualService와 DestinationRule은 함께 작동한다. VirtualService에서 부분집합을 참조하면 반드시 해당 부분집합을 정의하는 DestinationRule이 있어야 한다.
-
Istio는 강력한 진단 도구를 제공한다.
istioctl analyze,istioctl describe, Kiali와 같은 도구를 사용하면 문제를 빠르게 진단하고 해결할 수 있다. -
시각화 도구는 복잡한 문제를 이해하는 데 도움이 된다. Kiali와 같은 시각화 도구는 서비스 메시의 복잡한 관계와 설정을 직관적으로 볼 수 있게 해준다.
-
설정 변경 전 검증은 필수이다.
istioctl analyze를 사용하여 설정 변경을 적용하기 전에 검증하세요. 이렇게 하면 새로운 문제를 방지할 수 있다.
이제 간헐적 지연 문제를 해결했다. 다음 섹션에서는 더 심층적인 데이터 플레인 진단 기법을 다룬다.
4. 실습: 간헐적 지연 문제 트러블슈팅¶
서비스 메시에서 가장 까다로운 문제 중 하나는 간헐적으로 발생하는 지연 문제이다. 지연은 항상 발생하는 것이 아니라 가끔씩 나타나기 때문에 진단하기가 특히 어렵다. 이번 섹션에서는 이런 유형의 문제를 어떻게 재현하고, 진단하고, 해결하는지 알아보겠다.
참고: 간헐적 지연은 완전한 장애보다 더 오래 감지되지 않을 수 있다. 완전한 장애는 빠르게 감지되고 대응되지만, 간헐적 지연은 사용자 경험을 서서히 악화시키며 몇 주 동안 발견되지 않는 경우도 있다.

4.1 간헐적 지연 상황 재현¶
먼저 실제 운영 환경에서 발생할 수 있는 간헐적 지연 문제를 의도적으로 만들어 보겠다. 이를 통해 문제를 발견하고 해결하는 과정을 학습할 수 있다.
카오스 엔지니어링: 프로덕션 환경에서 의도적으로 문제를 일으켜 시스템의 회복력을 테스트하는 카오스 엔지니어링 접근 방식은 서비스 메시 운영에도 유용한다. 장애 상황을 미리 경험하여 실제 대응 능력을 향상시킬 수 있다.
Step 1: 이전 실습에서 생성한 설정 확인
# 현재 설정 확인
kubectl get vs,dr -n istioinaction
kubectl get pods -n istioinaction -l app=catalog --show-labels
앞서 만든 v1과 v2 두 버전의 catalog 서비스 중에서 v2 버전에 인위적인 지연을 추가해 보겠다.
Step 2: Version-v2 파드에 인위적인 지연 주입
# catalog v2 파드 중 첫 번째 파드 식별
CATALOG_POD_V2=$(kubectl get pods -l version=v2 -n istioinaction -o jsonpath={.items[0].metadata.name})
echo "지연을 주입할 파드: $CATALOG_POD_V2"
# 파드에 지연 주입 (1.5초 지연, 모든 요청이 아닌 일부 요청에만 적용)
kubectl -n istioinaction exec -c catalog $CATALOG_POD_V2 \
-- curl -s -X POST -H "Content-Type: application/json" \
-d '{"active": true, "type": "latency", "volatile": true, "latencyMS": 1500}' \
localhost:3000/blowup
이 명령은 catalog v2 파드에 약 1.5초의 지연을 주입한다. "volatile": true 설정으로 인해 모든 요청이 아닌 일부 요청에만 지연이 발생하여 간헐적 지연 문제를 시뮬레이션한다.
참고: 실제 프로덕션 환경에서 간헐적 지연은 다양한 원인으로 발생한다. 데이터베이스 연결 풀 부족, 가비지 컬렉션 일시 중지, 네트워크 혼잡, 공유 리소스 경합 등이 일반적인 원인이다.
Step 3: 지연 문제 확인
# 여러 번 서비스 호출하여 지연 확인
for i in {1..10}; do
time curl -s http://catalog.istioinaction.io:30000/items > /dev/null
echo "------------"
sleep 1
done
이 명령을 실행하면 일부 요청은 빠르게 완료되지만(약 0.1~0.2초), 일부는 1.5초 이상 지연된다. 이는 VirtualService에 설정된 가중치(v1: 20%, v2: 80%)와 "volatile" 지연 때문이다.
실행 결과 예시:
real 0m0.124s
user 0m0.003s
sys 0m0.005s
------------
real 0m1.632s
user 0m0.003s
sys 0m0.006s
------------
참고: 간헐적 지연이라도 사용자 경험과 비즈니스에 심각한 영향을 미칠 수 있다. 웹 사이트 로딩 시간이 3초를 넘으면 약 40%의 사용자가 이탈한다는 연구 결과가 있다.
4.2 타임아웃 설정으로 문제 완화¶
간헐적 지연 문제를 식별했으니, 첫 번째 대응 방법 중 하나는 타임아웃을 설정하는 것이다. 이를 통해 느린 응답으로 인한 사용자 경험 악화를 방지할 수 있다.
Step 1: VirtualService에 타임아웃 설정 추가
# 현재 VirtualService 설정 확인
kubectl get vs catalog-v1-v2 -n istioinaction -o yaml
# 타임아웃 설정 추가 (0.5초)
kubectl patch vs catalog-v1-v2 -n istioinaction --type json \
-p '[{"op": "add", "path": "/spec/http/0/timeout", "value": "0.5s"}]'
Step 2: 타임아웃 적용 확인
# 타임아웃 적용 후 설정 확인
kubectl get vs catalog-v1-v2 -n istioinaction -o yaml | grep timeout
# 여러 번 호출하여 결과 확인
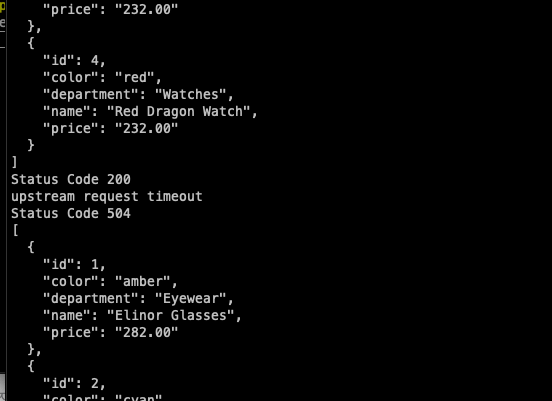
for i in {1..10}; do
curl -s -o /dev/null -w "%{http_code}\n" http://catalog.istioinaction.io:30000/items
sleep 0.5
done
이제 요청 중 일부는 504 Gateway Timeout 오류를 반환한다. 이는 설정된 0.5초 타임아웃이 적용되고 있음을 의미한다.
출력 예시:
주의사항: 타임아웃은 문제를 해결하는 것이 아니라 완화하는 방어 메커니즘이다. 근본 원인을 반드시 찾아 해결해야 한다.
4.3 로그 분석으로 문제 진단¶
타임아웃이 적용되었으니, 이제 로그를 분석하여 어떤 서비스가 지연을 일으키고 있는지 정확히 파악해 보겠다.
Step 1: 인그레스 게이트웨이 로그 분석
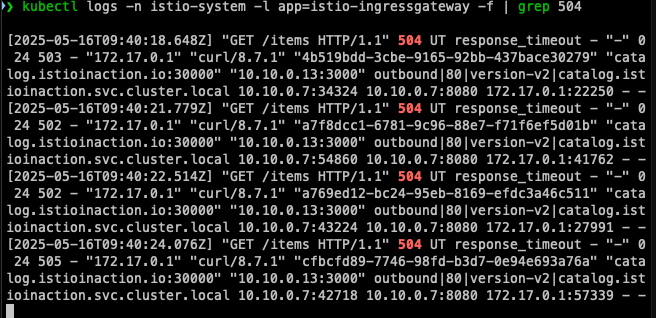
출력 예시:
[2025-05-10T02:42:13.528Z] "GET /items HTTP/1.1" 504 UT upstream_request_timeout - "-" 0 24 500 - "172.18.0.1" "curl/7.79.1" "6ef7d7f9-f607-9e08-9ac9-bb0fc1af9f26" "catalog.istioinaction.io" "10.10.0.14:3000" outbound|80|version-v2|catalog.istioinaction.svc.cluster.local 10.10.0.7:46182 172.18.0.2:8080 172.18.0.1:58242 - -
여기서 중요한 부분은 504 UT upstream_request_timeout이다. 'UT'는 "Upstream Timeout"을 의미한다. 이는 업스트림 서비스(catalog v2)의 응답 시간이 설정된 타임아웃(0.5초)을 초과했음을 나타낸다.
Step 2: JSON 형식 로그로 변경해 상세 정보 확인
# Istio ConfigMap 편집
kubectl edit -n istio-system cm istio
# 다음 내용을 meshConfig: 섹션 아래에 추가
# accessLogEncoding: JSON
# accessLogFormat: |
# {
# "start_time": "%START_TIME%",
# "method": "%REQ(:METHOD)%",
# "path": "%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%",
# "protocol": "%PROTOCOL%",
# "response_code": "%RESPONSE_CODE%",
# "response_flags": "%RESPONSE_FLAGS%",
# "response_code_details": "%RESPONSE_CODE_DETAILS%",
# "connection_termination_details": "%CONNECTION_TERMINATION_DETAILS%",
# "upstream_host": "%UPSTREAM_HOST%",
# "upstream_cluster": "%UPSTREAM_CLUSTER%",
# "upstream_local_address": "%UPSTREAM_LOCAL_ADDRESS%",
# "downstream_local_address": "%DOWNSTREAM_LOCAL_ADDRESS%",
# "downstream_remote_address": "%DOWNSTREAM_REMOTE_ADDRESS%",
# "requested_server_name": "%REQUESTED_SERVER_NAME%",
# "route_name": "%ROUTE_NAME%"
# }
**Step 3**: JSON 형식 로그 분석
```bash
# 새로운 요청 생성
curl -s http://catalog.istioinaction.io:30000/items > /dev/null
# JSON 형식 로그 확인
kubectl logs -n istio-system -l app=istio-ingressgateway -f | grep "response_code.*504" | jq
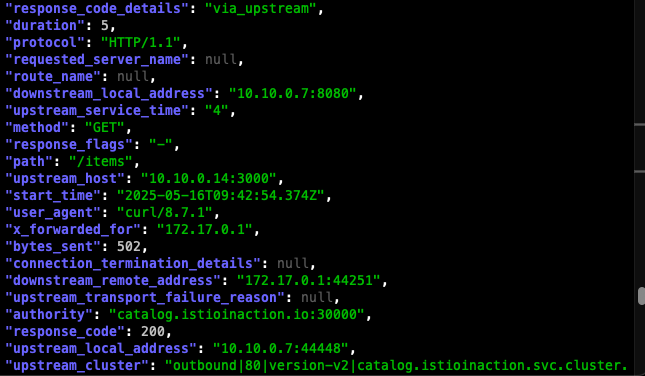
출력 예시:
{
"start_time": "2025-05-10T02:48:23.456Z",
"method": "GET",
"path": "/items",
"protocol": "HTTP/1.1",
"response_code": 504,
"response_flags": "UT",
"response_code_details": "upstream_request_timeout",
"upstream_host": "10.10.0.14:3000",
"upstream_cluster": "outbound|80|version-v2|catalog.istioinaction.svc.cluster.local",
"upstream_local_address": "10.10.0.7:41358",
"downstream_local_address": "10.10.0.7:8080",
"downstream_remote_address": "172.18.0.1:60234",
"requested_server_name": "",
"route_name": "default"
}
이 설정은 타임아웃이 발생한 서비스를 명확하게 보여준다. 이제 이 문제를 해결한다.
4.4 Prometheus로 문제가 있는 파드 식별¶
로그 분석은 개별 문제를 식별하는 데 유용하지만, 전체적인 패턴을 파악하는 데는 메트릭 분석이 더 효과적이다. Prometheus를 사용하여 문제가 있는 파드를 더 정확히 식별한다.
Step 1: Prometheus UI 접속
Step 2: 지연 관련 쿼리 실행
Prometheus UI에서 다음 쿼리를 실행한다:
histogram_quantile(0.95, sum(rate(istio_request_duration_milliseconds_bucket{reporter="destination", destination_service_name="catalog", response_code="200"}[1m])) by (destination_workload, le))
이 쿼리는 catalog 서비스에 대한 성공적인 요청을 워크로드별로 보여준다.
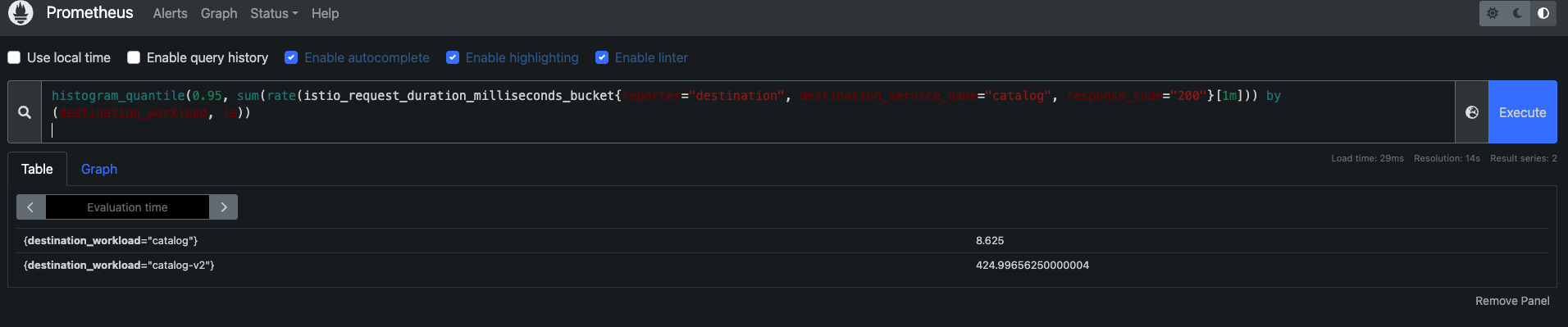
이 결과에서 catalog-v2 워크로드의 요청이 특히 높은 것을 확인할 수 있다.
Step 3: 오류율 쿼리 실행
타임아웃으로 인한 오류율을 확인하기 위해 다음 쿼리를 실행한다:
sum(rate(istio_requests_total{reporter="source", destination_service_name="catalog", response_code="504"}[1m])) by (destination_workload) / sum(rate(istio_requests_total{reporter="source", destination_service_name="catalog"}[1m])) by (destination_workload)
이 쿼리는 각 워크로드별 504 오류의 비율을 보여준다.

참고: 프로덕션 환경에서는 이러한 쿼리를 기반으로 알림 규칙을 설정하는 것이 좋다. 95번째 백분위수 지연 시간이 특정 임계값을 초과하거나 오류율이 급증할 때 알림을 받을 수 있다.
4.5 문제 해결 전략¶
간헐적 지연 문제를 식별했다. 실제 환경에서는 다음과 같은 전략을 사용할 수 있다:
-
트래픽 전환: 일시적으로 문제가 있는 서비스 버전에서 트래픽을 제거한다.
-
서킷 브레이커 설정: 문제가 있는 서비스에 서킷 브레이커를 적용하여 시스템이 자동으로 실패 상태에서 회복될 수 있도록 한다.
cat <<EOF | kubectl apply -f - apiVersion: networking.istio.io/v1alpha3 kind: DestinationRule metadata: name: catalog namespace: istioinaction spec: host: catalog.istioinaction.svc.cluster.local trafficPolicy: outlierDetection: consecutive5xxErrors: 3 interval: 10s baseEjectionTime: 30s subsets: - name: version-v1 labels: version: v1 - name: version-v2 labels: version: v2 EOF

- 근본 원인 제거: 실제 환경에서는 문제의 근본 원인을 파악하고 해결해야 한다. 인위적으로 추가한 지연이므로 이를 제거하면 된다.
Step 4: 이 실습에서 배운 점
간헐적 지연 문제를 다루면서 다음과 같은 중요한 교훈을 얻는다:
-
타임아웃은 필수적인 방어 메커니즘이다: 적절한 타임아웃을 설정하면 느린 서비스가 전체 시스템의 성능을 저하시키는 것을 방지할 수 있다.
-
로그와 메트릭은 상호 보완적이다: 로그는 개별 이벤트에 대한 자세한 정보를 제공하고, 메트릭은 전체적인 패턴과 추세를 보여준다. 둘 다 문제 해결에 필수다.
-
복원력 패턴이 중요하다: 서킷 브레이커, 재시도, 타임아웃과 같은 패턴을 적용하면 일시적인 문제로부터 시스템을 보호할 수 있다.
-
점진적 롤아웃은 위험을 줄인다: 가중치 기반 라우팅을 사용하여 새 버전을 점진적으로 롤아웃하면 문제가 발생했을 때 영향을 최소화할 수 있다.